

목차
- 파이썬 dictionary 타입 변수 활용 예제 이전 포스팅 참고 학습
- 리눅스 top 프로세스 CPU 사용량 확인 명령 예제 이전 포스팅 참고 학습
- 파이썬 전체 프로세스 CPU 사용량 출력 예제 이전 포스팅 참고 학습
- 파이썬 CPU 사용량, 프로세스명으로 dict 파싱 예제
- 파이썬 파싱 dcit 출력 예제

파이썬 dictionary 타입 변수 활용 예제 이전 포스팅 참고 학습
오늘 포스팅 주제는 파이썬에서 특정 프로세스 CPU 사용량을 dict 타입의 변수로 파싱하는 예제입니다. 키는 프로세스명이고 값은 CPU 사용량입니다. 프로그래밍을 수행하다보면 특정 프로세스가 유독 많은 CPU를 사용할 때가 있습니다. 이를 위해서 정해진 시간마다 모든 프로세스들의 CPU 사용량을 확인하여 최적화할 필요가 있습니다.
오늘 예제를 실행하기에 앞서 파이썬 환경에서 Dictionary 타입 변수는 어떻게 활용하는지 모르신다면 아래 링크를 참고하여 학습해주세요.
2023.07.25 - [Python] - [Python] Dictionary 활용 예제 - 3(키 값 있는지 확인하고 가져오기, 전체 키 및 값 가져오기, 가져오면서 삭제)
[Python] Dictionary 활용 예제 - 3(키 값 있는지 확인하고 가져오기, 전체 키 및 값 가져오기, 가져오면
목차 get(key, default) (키로 값 찾기, 없으면 기본 값 설정 예제) items() (전체 값 출력 예제) keys() (전체 키 출력 예제) pop(key, default) (키로 값 가져오고 삭제, 없으면 기본 값 설정 예제) popitem() (마지
salguworld.tistory.com
리눅스 top 프로세스 CPU 사용량 확인 명령 예제 이전 포스팅 참고 학습
또한, 본 예제는 리눅스 환경에서 실행됩니다. 따라서 리눅스 환경에서 프로세스들의 CPU 사용량을 확인하려면 top와 같은 명령을 사용해야합니다. 따라서 리눅스의 top 명령 사용법을 알아야합니다.
예를들어 top를 그냥 실행하면 프로그램이 종료되지않고 계속 무제한으로 업데이트를 진행합니다. 우리는 검색 시점의 1번만 값을 참고하면되기때문에 다양한 옵션을 같이 활용해야합니다.
아직 top 사용법을 잘 모르신다면 아래 링크를 참고해주세요.
2023.08.03 - [Linux] - [Linux] top 활용 프로세스 CPU, 메모리 사용량 확인(정렬)
[Linux] top 활용 프로세스 CPU, 메모리 사용량 확인(정렬)
목차 리눅스에서 top란? 대표적인 top 명령어 설명 top 결과창 항목별 설명 프로세스 실시간 리소스 사용량 확인 예제 CPU 사용량 순서 정렬 메모리 사용량 순서 정렬 1. 리눅스에서 top란? top는 리눅
salguworld.tistory.com
파이썬 전체 프로세스 CPU 사용량 출력 예제 이전 포스팅 참고 학습
마지막으로 이전 포스팅에서는 전체 프로세스 CPU 사용량을 확인하여 출력하는 예제를 알아보았습니다. 마찬가지로 top 를 활용하였으며 파싱은 없고 출력예제입니다. 하지만 오늘 포스팅을 알아보기 이전에 먼저 알아본다면 도움이 될 수 있습니다. 따라서 파이썬에서 전체 프로세스 CPU 사용량 출력 예제가 궁금하시다면 아래 링크를 참고해주세요.
2023.08.30 - [Python] - [Python/Linux] 파이썬 전체 프로세스 CPU 사용량 가져오기 예제(popen, top)
파이썬 CPU 사용량, 프로세스명으로 dict 파싱 예제
아래는 파이썬에서 프로세스명을 Key로 CPU 사용량을 Value로 파싱하여 dict 변수에 저장하는 예제입니다.
import subprocess
import re
def parse_top_output(output):
processes = {}
lines = output.decode().split('\n')
for line in lines:
if re.match(r'\s*\d+', line):
columns = line.split()
process_name = columns[11]
cpu_usage = float(columns[8])
processes[process_name] = cpu_usage
return processes
# top 명령어 실행하고 결과 가져오기
cmd = ['top', '-b', '-n', '1']
result = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
top_output = result.stdout
# 결과를 파싱하여 딕셔너리에 저장
processes_dict = parse_top_output(top_output)

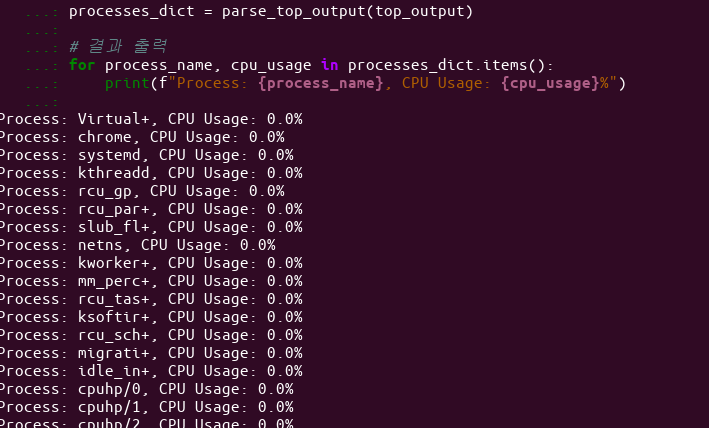
파이썬 파싱 dcit 출력 예제
아래는 위 예제에서 구한 프로세스의 CPU 사용량을 모두 출력하는 예제입니다.
import subprocess
import re
def parse_top_output(output):
processes = {}
lines = output.decode().split('\n')
for line in lines:
if re.match(r'\s*\d+', line):
columns = line.split()
process_name = columns[11]
cpu_usage = float(columns[8])
processes[process_name] = cpu_usage
return processes
# top 명령어 실행하고 결과 가져오기
cmd = ['top', '-b', '-n', '1']
result = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
top_output = result.stdout
# 결과를 파싱하여 딕셔너리에 저장
processes_dict = parse_top_output(top_output)
# 결과 출력
for process_name, cpu_usage in processes_dict.items():
print(f"Process: {process_name}, CPU Usage: {cpu_usage}%")
목차
- 파이썬 dictionary 타입 변수 활용 예제 이전 포스팅 참고 학습
- 리눅스 top 프로세스 CPU 사용량 확인 명령 예제 이전 포스팅 참고 학습
- 파이썬 전체 프로세스 CPU 사용량 출력 예제 이전 포스팅 참고 학습
- 파이썬 CPU 사용량, 프로세스명으로 dict 파싱 예제
- 파이썬 파싱 dcit 출력 예제
파이썬 dictionary 타입 변수 활용 예제 이전 포스팅 참고 학습
오늘 포스팅 주제는 파이썬에서 특정 프로세스 CPU 사용량을 dict 타입의 변수로 파싱하는 예제입니다. 키는 프로세스명이고 값은 CPU 사용량입니다. 프로그래밍을 수행하다보면 특정 프로세스가 유독 많은 CPU를 사용할 때가 있습니다. 이를 위해서 정해진 시간마다 모든 프로세스들의 CPU 사용량을 확인하여 최적화할 필요가 있습니다.
오늘 예제를 실행하기에 앞서 파이썬 환경에서 Dictionary 타입 변수는 어떻게 활용하는지 모르신다면 아래 링크를 참고하여 학습해주세요.
2023.07.25 - [Python] - [Python] Dictionary 활용 예제 - 3(키 값 있는지 확인하고 가져오기, 전체 키 및 값 가져오기, 가져오면서 삭제)
[Python] Dictionary 활용 예제 - 3(키 값 있는지 확인하고 가져오기, 전체 키 및 값 가져오기, 가져오면
목차 get(key, default) (키로 값 찾기, 없으면 기본 값 설정 예제) items() (전체 값 출력 예제) keys() (전체 키 출력 예제) pop(key, default) (키로 값 가져오고 삭제, 없으면 기본 값 설정 예제) popitem() (마지
salguworld.tistory.com
리눅스 top 프로세스 CPU 사용량 확인 명령 예제 이전 포스팅 참고 학습
또한, 본 예제는 리눅스 환경에서 실행됩니다. 따라서 리눅스 환경에서 프로세스들의 CPU 사용량을 확인하려면 top와 같은 명령을 사용해야합니다. 따라서 리눅스의 top 명령 사용법을 알아야합니다.
예를들어 top를 그냥 실행하면 프로그램이 종료되지않고 계속 무제한으로 업데이트를 진행합니다. 우리는 검색 시점의 1번만 값을 참고하면되기때문에 다양한 옵션을 같이 활용해야합니다.
아직 top 사용법을 잘 모르신다면 아래 링크를 참고해주세요.
2023.08.03 - [Linux] - [Linux] top 활용 프로세스 CPU, 메모리 사용량 확인(정렬)
[Linux] top 활용 프로세스 CPU, 메모리 사용량 확인(정렬)
목차 리눅스에서 top란? 대표적인 top 명령어 설명 top 결과창 항목별 설명 프로세스 실시간 리소스 사용량 확인 예제 CPU 사용량 순서 정렬 메모리 사용량 순서 정렬 1. 리눅스에서 top란? top는 리눅
salguworld.tistory.com
파이썬 전체 프로세스 CPU 사용량 출력 예제 이전 포스팅 참고 학습
마지막으로 이전 포스팅에서는 전체 프로세스 CPU 사용량을 확인하여 출력하는 예제를 알아보았습니다. 마찬가지로 top 를 활용하였으며 파싱은 없고 출력예제입니다. 하지만 오늘 포스팅을 알아보기 이전에 먼저 알아본다면 도움이 될 수 있습니다. 따라서 파이썬에서 전체 프로세스 CPU 사용량 출력 예제가 궁금하시다면 아래 링크를 참고해주세요.
2023.08.30 - [Python] - [Python/Linux] 파이썬 전체 프로세스 CPU 사용량 가져오기 예제(popen, top)
파이썬 CPU 사용량, 프로세스명으로 dict 파싱 예제
아래는 파이썬에서 프로세스명을 Key로 CPU 사용량을 Value로 파싱하여 dict 변수에 저장하는 예제입니다.
import subprocess
import re
def parse_top_output(output):
processes = {}
lines = output.decode().split('\n')
for line in lines:
if re.match(r'\s*\d+', line):
columns = line.split()
process_name = columns[11]
cpu_usage = float(columns[8])
processes[process_name] = cpu_usage
return processes
# top 명령어 실행하고 결과 가져오기
cmd = ['top', '-b', '-n', '1']
result = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
top_output = result.stdout
# 결과를 파싱하여 딕셔너리에 저장
processes_dict = parse_top_output(top_output)
파이썬 파싱 dcit 출력 예제
아래는 위 예제에서 구한 프로세스의 CPU 사용량을 모두 출력하는 예제입니다.
import subprocess
import re
def parse_top_output(output):
processes = {}
lines = output.decode().split('\n')
for line in lines:
if re.match(r'\s*\d+', line):
columns = line.split()
process_name = columns[11]
cpu_usage = float(columns[8])
processes[process_name] = cpu_usage
return processes
# top 명령어 실행하고 결과 가져오기
cmd = ['top', '-b', '-n', '1']
result = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
top_output = result.stdout
# 결과를 파싱하여 딕셔너리에 저장
processes_dict = parse_top_output(top_output)
# 결과 출력
for process_name, cpu_usage in processes_dict.items():
print(f"Process: {process_name}, CPU Usage: {cpu_usage}%")